智谱发布重磅技术报告,国产开源大模型实力崛起
时间:2025-10-02 19:00
小编:星品数码网
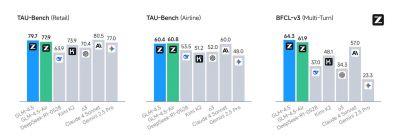
在刚刚过去的一个月中,智谱科技引发了人工智能领域的巨大关注,发布了其开源的新一代旗舰模型——国产开源大模型,标志着国内研发实力的显著提升。这个新模型不仅成功将编码和智能体能力进行了原生融合,还在全球范围内的12项硬核测试中斩获了第三名的优异成绩,成为当前所有国产及开源模型中的佼佼者。
智谱发布消息后,瞬间在社交网络上引发热议,官方推文的浏览量突破120万次,模型的下载和使用量在Hugging Face榜单上连续七天取得榜首,成为AI圈内的热门话题。众多研究者和开发者纷纷分享该模型在各种基准测试中的优异表现,展现出广泛的关注和认可。
就在智谱的热度不断攀升之际,OpenAI也发布了其备受期待的gpt-oss系列模型,社交上的用户迅速将两者相提并论,结果显示智谱的新模型的表现依然突出,令很多人对其背后的技术细节充满好奇。经过长时间的期待,智谱终于如愿以偿地发布了技术报告,详细介绍了其新模型的设计思路和实现过程。
该技术报告的标题为《Agentic, Reasoning, and Coding Foundation Models》,可以通过以下链接访问:[技术报告](https://arxiv.org/abs/2508.06471)。报告不仅阐述了该模型在预训练和后训练阶段的详细过程,还特别介绍了为其量身打造的开源强化学习(RL)框架,展示了其在灵活性和效率上的优势。这份报告在Hugging Face上也被用户投票选为“今日最佳”。
智谱的研究团队指出,现今的大语言模型(LLM)正在从一个通用知识库演变为一个通用问题求解器,旨在实现更高级别的认知能力。这一演变不仅需要模型在特定任务中展现专家级的表现,还需在复杂问题解决、泛化能力和自我改进等方面实现突破。因此,智谱将重点聚焦于提升模型与外部工具和现实世界的互动能力,在数学、科学领域解决多步骤问题的复杂能力,以及处理现实世界软件工程任务的高级能力。
针对这些需求,智谱采用了混合专家(MoE)架构,大幅提升训练和推理时的计算效率,并在注意力机制方面也进行了创新性设计。他们探索了更深层的模型架构,以便在提升模型能力的同时降低计算消耗。智谱团队在技术细节上特别提到,他们在模型的自注意力机制中采用了分组查询注意力的设计,大幅提升了模型在多个标准测试上的表现。
在训练过程中,智谱的模型经历了两个阶段的预训练,使用了来自多种来源的海量数据,提高了模型的准确性和稳健性。尤其是在高质量的数据上采样方面,智谱在数学、科学和编程相关的数据上进行了细致的优化,以提升模型的表现。
特别值得一提的是,智谱为新模型打造的RL框架不仅提高了训练效率,还突破了强化学习中的常见瓶颈,通过将环境交互引擎与训练引擎分离,极大提高了长序列处理的效率。这些整体性的设计使得新模型能够高效处理复杂任务,更加灵活地适应不同应用场景。
在经过多阶段的训练后,智谱的新模型不仅在通用领域表现出色,更在软件工程、信息检索等具体应用上达到了前所未有的水平。经过评估,智谱的模型在多个基准测试上均展现了超越现有顶尖模型的实力,包括在SWE-bench和Terminal-Bench等实际任务中表现优于众多竞争对手。
此次技术报告的发布,为关注国产开源大模型发展的研究人员和行业从业者提供了宝贵的参考资料,展示了智谱在大模型领域的研究方向和潜在的应用前景。随着国产开源大模型的不断崛起,预计将在各行各业带来更多创新的解决方案,推动人工智能技术更深层次的发展。
智谱这次发布的重磅技术报告,不仅是对其模型性能的一次汇报,更是为同行业的研究者们提供了深入理解国产大模型背后技术秘诀的一把钥匙,对于推动整个行业的进步具有重要的意义。
