MiniMax发布支持百万Token的推理模型M1,引领AI长文本处理新潮流
时间:2025-06-17 18:05
小编:星品数码网
在经历了近半年的推理模型市场热潮之后,MiniMax于6月17日隆重推出并开源了其首款革命性推理模型M1。这款模型凭借支持高达100万Token的上下文输入长度,一举成为业内的佼佼者,相比于DeepSeek的R1模型,其上下文长度提升了惊人的8倍。M1还具备业内最长的8万Token推理输出能力,为 AI 的文本生成和处理能力设置了新的标杆。
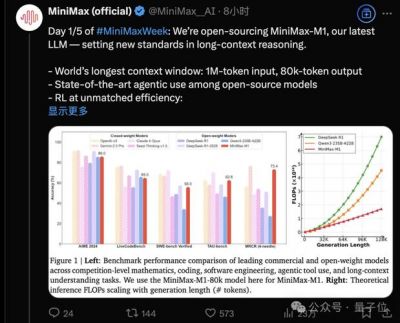
关于M1模型的结构,MiniMax团队表示,M1的创新之处在于其采用了混合专家(Mixture of Experts, MoE)架构,并结合了一种全新的“闪电注意力”(Lightning Attention)机制。MoE架构的关键在于通过“专家”模式,模型在接收到问题输入时能够优先激活其最相关的几个“专家”,进行高效的推理与输出。这种方法极大地提高了模型在处理长文本时的资源利用效率,进一步降低了所需的计算能力。“闪电注意力”机制则是为了突破传统Transformer架构所带来的记忆瓶颈,优化了长文本推理过程中的计算资源利用率,技术报告显示,在生成10万个Token的场景下,M1所需的推理算力仅为DeepSeek R1的25%。
AI在处理长文本时的能力显得尤为重要,这关系到智能体的长期记忆和多步骤操作的实现。MiniMax在早期的讨论中提到,无论是单Agent系统的记忆需求,还是多Agent系统内部的复杂通信,日益优化的上下文管理能力都是不可或缺的。这些背景信息为M1模型的成功奠定了基础。
值得注意的是,MiniMax在M1的训练阶段采用了相对高效的方式。技术报告显示,在仅用512张英伟达H800 GPU的配置下,M1的整个强化学习训练阶段仅用时三周完成。其租赁成本约为53.47万美元,折合人民币大约为384万元,可谓具备相对成本效益。
在定价策略方面,MiniMax力求在保证模型能力的前提下,提供业内最具竞争力的价格。官方透露,M1模型 API 服务的费用根据输入长度分为多个区间。在输入长度0-32k时,模型使用成本为0.8元/百万Token,而输出成本为8元/百万Token;在32k-128k的输入长度区间,输入价格为1.2元/百万Token,输出为16元/百万Token;在最长的128k-1M输入长度阶段,输入价格提升至2.4元/百万Token,输出则为24元/百万Token。这一灵活的“区间定价”策略与近期另一大模型厂商豆包的相似,不仅突显了行业内愈发严峻的竞争形势,也让更多企业可以更经济地使用高性能的AI模型。
火山引擎总裁谭待曾指出,许多模型厂商通过功能差异化定价,但在同结构同参数的模型中,实际影响成本的主要因素是上下文窗口长度。他认为,通过确定不同窗口长度的消费区间,可以有效促进深度学习模型的广泛应用,尤其是在大规模任务执行中,降低Token消耗至关重要。
MiniMax的商业模式也是一个值得关注的亮点。与一些竞争者(如智谱)提供定制化服务不同,MiniMax选择了一条更为直接的B端纯API模式,这一决策可能使其在市场迅速变动时更具灵活性与适应性。其内部团队也相应分为文本、视觉(视频与图像)和语音三大模块,目前每一块都有对应的C端产品。
除了推出M1模型,MiniMax还预告将在的工作日内发布其他相关的更新,涉及语音、视频等领域,这将进一步增强其产品的整体生态。随着M1的发布,MiniMax在长文本处理的AI模型市场中开辟了新的领域,展现了强大的技术实力和布局前瞻性。
在AI行业竞争日益激烈的背景下,MiniMax的创新与适应能力值得关注,其成功推出M1模型不仅是对技术的追求,也是对市场需求深刻理解的体现。未来,随着AI应用场景的不断扩展,像MiniMax这样的公司必将在长文本处理、智能体互动等领域继续引领行业潮流。
