eepSeek-R1引领LLM推理革命:群体相对策略优化的崭新应用
时间:2025-05-28 18:25
小编:星品数码网
编辑:KingHZ
在大语言模型(LLMs)的发展历程中,eepSeek-R1的推出是一场引爆LLM推理革命的重大创新。这一进展的核心在于其独特的微调算法——群体相对策略优化(Group Relative Policy Optimization,简称GR),它引领着未来LLM训练的新方向。
LLM的推理能力,简单是指模型通过一系列推导和训练手段,增强其处理复杂任务的能力。从技术层面看,推理的定义涉及到模型在生成最终答案之前,能够先产生一系列中间步骤的能力。这一过程通常被称为“思维链”(Chain-of-Thought,CoT推理)。在CoT推理中,模型不仅仅是通过回忆某个事实来给出答案,而是需要结合多个中间推理步骤,来得出最终的。
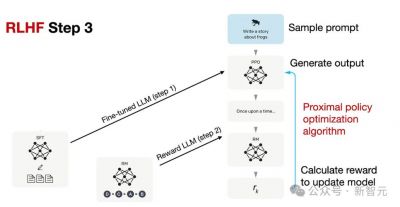
传统的LLM训练多依赖于人类反馈(RLHF),这一过程一般包括三个阶段:使用大规模语料进行通用语言模式和知识的学习;通过人工标注的任务数据进一步训练,旨在提高模型在特定任务上的表现;,基于人类偏好的反馈,对模型进行优化,从而提升其交互体验与安全性。
而在R1及GR优化方法的引入之后,这一模式正在发生根本性的变革。GR的核心创新在于剔除了传统RLHF中的“评论家”(价值模型),并采用了一种相对质量评估的方法。这种方法通过对策略模型生成的多组回答进行质量对比,直接计算优势函数,从而显著降低了推理模型的计算需求,使得即便是资源有限的小型团队也能开发出具有复杂推理能力的模型。
在GR的训练流程中,模型的训练过程变得更加简单高效。通过对不同输出进行相对评估,可以快速选择最佳答案,进而对模型进行微调。具体GR方法允许模型在面对逻辑推理或数学问题时,更加准确地进行决策。这种引导式学习,极大提高了模型在多步骤推理任务上的表现。从实践中来看,GR方法不仅降低了训练成本,还提高了模型生成高质量答案的能力。
eepSeek-R1所引发的革命并不仅限于推理能力的提升。新技术的发展还激发了对于其他潜在创新应用的探索。例如,随着对RLHF及其变种的深入研究,学者们开始关注如何进一步提升模型的多样性和稳定性,以应对当前训练过程中常见的熵崩溃和奖励噪声问题。
在具体的实现上,开放源代码的解耦裁剪与动态采样策略优化(Decoupled Clip and Dynamic Sampling Policy Optimization,简称DCDSPO)成为了另一个研究热点。这一方法通过提升系统输出样本的多样性,避免长文本中token学习效果不佳的问题,进而提升了模型的训练效率。
eepSeek-R1在多步推理中所展现出的“反思”及“回溯”能力,引起了研究者的广泛关注。这种在训练过程中突现的自我调整能力,可能为未来的优化提供新的研究方向,也使得模型在处理复杂任务时,能够更加灵活和高效。
来看,eepSeek-R1的创新不仅仅体现在算法的优化,更在于开创了一条将模型推理能力作为核心目标的新训练路径。通过群体相对策略优化(GR),LLMs的推理过程得以有效简化,进而实现了更高效的训练方式和更加出色的实际应用表现。随着技术的不断进步,未来的LLM在处理复杂推理任务时,必将展现出超乎想象的能力,推动整个人工智能领域的进一步发展。
在的日子里,eepSeek还将持续探索多样化的应用场景,期待其在更广泛领域产生积极的影响。无论是教育、科技还是其他行业,eepSeek-R1的影响力,将在不久的将来渗透到更多的领域,改变人们的工作和生活方式。
