扩散模型新突破:高效代码生成速度高达传统工具的10倍
时间:2025-07-12 06:55
小编:星品数码网
在技术迅速发展的今天,扩散模型正展现其超凡的潜力,尤其在代码生成领域的应用。之前我们虽然可以看到扩散模型主要用于生成图像和视频,但现在,它们在编写高质量代码方面也展现出同样的卓越性能。
这项新技术的推出,不仅是对传统自回归模型的颠覆,更是为开发者开启了全新的编程体验。传统的自回归模型通常采用“从左到右”的方式逐字生成,这种方式在生成代码时存在着不小的局限性。例如,一旦生成了某个部分的代码,开发者往往难以回头进行调整。而扩散模型则利用“从噪声到结构化输出”的独特方式,大大提高了生成速度和灵活性。这种新方法能够代替自回归生成的逐步性质,使得模型在生成过程中能够考虑多个token, 不再仅仅局限于前面的生成内容。
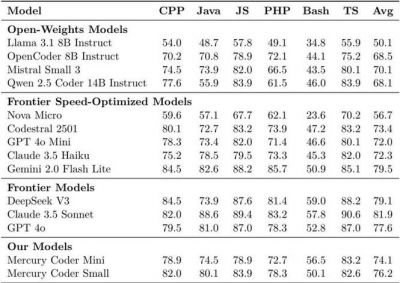
实测数据显示,这种基于扩散模型的新技术能够在处理相同的编程任务时,其代码生成速度可以达到传统工具的10倍,显著缩短了开发周期。这一效果在高性能计算硬件(如H100 GPU)上表现尤为突出,达到了极高的吞吐量。通过利用近年来发展出的高效训练和推理优化技术,尤其是低阶算子优化和超参数调优工具,扩散模型得以充分发挥其潜力。
扩散模型的核心创新在于其生成流程。该流程始于真实文本,通过逐步引入噪声(例如随机替换和删除token),最终形成完全随机的噪声序列。在推理阶段,利用反向过程模型从随机噪声开始,通过迭代优化逐步去噪,生成符合真实文本分布的代码。这一过程中,通过同时调整多个token,反向过程比逐词生成显著提高了生成效率。
扩散模型在生成文本时还借助了先进的硬件利用技术。通过优化文本生成的调度方式,以及采用混合精度量化等方法,扩散模型能够在一次前向传播中同时预测多个token。这一机制使得GPU的计算能力得到了充分发挥,极大提高了其利用率。实测数据表明,基于这种机制的新一代模型在Copilot Arena基准测试中的响应时间能够缩短至其他工具的四分之一,同时硬件资源占用也减少了60%。这种高效的运算模式特别适合在动态环境中工作,能够根据任务的复杂程度自行调整去噪步数,确保精度与效率之间的平衡。
扩散模型在代码生成中的另一个优势在于其强大的错误纠正能力。由于其不再局限于自回归生成的单向特性,在去噪过程中引入上下文双向关联,这使得模型能够更好地理解文本前后语境,有效发现并纠正错误。在代码编写任务中,该模型能够智能地处理代码逻辑漏洞,并自动修正函数级参数,从而大大提高代码的准确性与可靠性。
不过,尽管扩散模型在高效代码生成方面表现出色,当前持续集成(CI/CD)能力却未能同步提升。过去,在LLMs (大型语言模型)出现在软件开发领域之前,CI/CD的速度就已成为一个主要瓶颈,开发者们在测试时经常面临等待拉取请求的漫长时光。尽管新模型能够实现超高速的代码生成,但一旦代码更改仍需数小时进行测试,便难免让人失望。这引发了一个问题:如何缓解超快生成速度与当前CI/CD能力之间的矛盾。有观点认为,可以通过投入更多计算资源来解决,但对于大多数公司增加CI预算并不是易事。这一矛盾提醒我们,单靠技术的提升,往往不能解决流程中的所有问题,反而需要从整体架构上进行改进,以实现资源使用和开发效率的双重提升。
这一系列的技术突破和应用进展背后,是一支来自斯坦福、UCLA与康奈尔大学的强大团队。他们的联合创始人包括扩散模型的共同发明人Stefano Ermon,以及曾在Meta FAIR担任研究科学家的Aditya Grover及其他享有声誉的学者。团队成员的背景及其对大模型优化的关注,使得扩散模型的发展和应用变得更加前沿和有针对性。
扩散模型的崛起为软件开发领域带来了革命性的改变。其超高效率、灵活性以及强大的错误纠正能力,预示着未来的编程方式将更加智能化和高效化。同时,这也为如何提升持续集成能力提供了思考的方向,尽管目前仍面临一些挑战,但随着技术的进步,我们有理由相信,这一切将不再遥远。
