苹果最新论文质疑AI推理能力:大模型仅为‘模式匹配’?
时间:2025-06-11 04:05
小编:星品数码网
在人工智能领域,苹果公司最近发布的一篇论文引起了广泛的关注与讨论。这篇论文毫不留情地质疑了目前流行的大型模型是否具备真正的推理能力,认为它们仅仅是“模式匹配”的结果。这一观点不仅对技术界产生了冲击,也引发了对人工智能未来发展的深思。
论文的作者团队中包括多位知名学者,如谷歌大脑的创始人Samy Bengio。他们指出,无论是DeepSeek、o3-mini还是Claude 3.7等模型,都未能在复杂任务中展示真正的思考能力。当碰到高复杂度的任务时,这些模型难以保持稳定表现,甚至在理论上给予它们足够的时间和算力也无济于事。
模型的推理能力存疑
苹果团队在论文中并未一味否定现有模型的成果,而是表示当前对推理能力的评估存在明显不足。现行的评价标准通常集中在模型最终回答的正确性上,这种评估却忽略了思考过程的重要性。例如,模型在解决过程中是否逻辑一致,或是否出现了不必要的绕路,这些都未被充分重视。
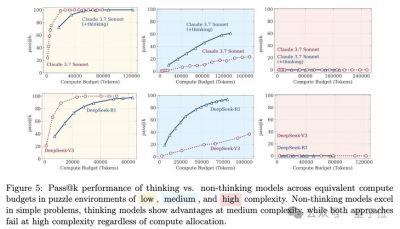
为了更深入地检视推理能力,苹果研究团队设计了四类谜题场景,这些场景既可以精确控制难度,又保持逻辑结构的一致性。通过实验,他们观察到不同模型在处理这些谜题时的表现差异,尤其是在低、中、高复杂度任务下的反应。
收获与发现
令人惊讶的是,论文中提到,在较低复杂度的任务中,未启用思考机制的标准语言模型反而表现得更好。它们准确性更高,效率更佳,显示出思考并不总是提升表现的必要条件。当任务复杂度适度增加时,具备思考能力的推理模型的优势便显现出来,额外的思考确实为找到解决方案提供了帮助。
但当问题的复杂度进一步提升至某个阈值时,无论是哪种模型,其表现均出现明显下降,准确率按直线下降至零。这一点极具启示性,表明现有的推理模型在面对高难度问题时,表现出了一种“推理努力反向缩放”的现象。随着复杂度的加大,模型在思考过程中逐渐减少了探索的广度,甚至在计算资源未耗尽的情况下主动放弃了思考。这一观察给研究者提供了宝贵的实验数据,也表明很有必要重新审视现有模型的限制与潜能。
对苹果的未来展望
在广泛讨论这一论文后,许多人开始考量苹果在人工智能领域的现状。的确,苹果在AI研究方面的进展并不如人意,尤其是与竞争对手相比。一年以来,尽管苹果对AI的重视程度不断提升,许多功能仍然未能达成预期,甚至伴随着技术的不成熟而频频遭受质疑。
例如,去年WWDC上推出的Apple Intelligence原本充满期待,然而其后续功能屡次延期,并在用户反馈中暴露出不少问题。更为严峻的是苹果在内部推进AI产品和功能时所碰到的重重困难:从资源分配不足到高层管理团队对AI长远价值的迟疑,苹果的AI发展策略似乎在步步为难。
尽管如此,苹果也并非完全沦为竞争对手的后进者。历史上,苹果公司一直以来以优雅的设计与用户体验闻名,它们更倾向于在技术成熟后再推出解决方案。尽管当前的落后是一个短期现象,但苹果若能借鉴此次研究的发现,改善其模型的思考机制与推理能力,未来依然可能迎来新一轮的崛起。
苹果最新论文的发布,不仅对现有AI模型的推理能力提出了质疑,也为未来AI研究的方向提供了新的思考方式。提升推理模型的质量、提高评估机制的标准,将是当前迫在眉睫的工作。面对技术的飞速发展,不同厂商之间的竞争也将愈发激烈,如何打破现有的计算瓶颈,实现真正的推理能力,将是未来AI发展的关键。
