清华与蚂蚁联合团队推出AReaL-boba²,推动异步强化学习技术革命
时间:2025-06-08 21:55
小编:星品数码网
最近,清华大学交叉信息院与蚂蚁技术研究院的科研团队联合推出了名为AReaL-boba²的异步强化学习系统,这一新技术的问世标志着强化学习领域的一次重要技术革命。强化学习(Reinforcement Learning)中的一项关键技术,近年来备受关注,其应用范围从自然语言处理到决策制定,再到复杂系统优化,呈现出多样化的发展前景。
强化学习的基本原理可以形象化为训练宠物的过程:当宠物表现出良好的行为时,给予其奖励;反之则不予奖励,甚至给予轻微惩罚。在人工智能模型中,这一过程往往表现为生成内容与训练反馈的交替过程。基于这一机制,模型能够不断优化其生成的结果,提高决策的准确性和效率。
有鉴于此,AReaL-boba²的推出引发了业界的广泛关注。其最大亮点在于实现了流式数据的不断生成与并行训练,极大提升了强化学习的训练速度。这一系统不仅在技术上实现了创新,同时研究团队还在Qwen3系列模型的基础上开源了相关的强化学习训练模型,使得开发者们能够从中受益,进一步促进了学术界与产业界的合作。
在技术细节上,AReaL-boba²包含多个核心模块,包括生成器、评估器、训练器和控制器。这些模块的设计旨在实现彻底的异步操作,意味着生成和训练过程中无需等待彼此的完成。举例生成器能够在更新模型权重的同时继续其生成任务,提升了GPU资源的利用率,避免了因等待而造成的空闲。
相比于传统的强化学习机制,AReaL-boba²在实现高效训练的同时,亦面临挑战。当生成与训练阶段紧密耦合时,训练过程往往会受到生成时间的严重影响,进而诱发“版本滞后”问题。这种问题在大型模型中表现尤为明显,因为生成的输出长度通常因提示内容差异而波动,出现快慢不均的情况。AReaL-boba²团队通过设计创新算法,有效解决了生成数据与模型版本之间的匹配问题。
例如,该团队引入了标准化策略版本(η)控制生成数据的老旧程度,保障训练稳定性。同时,采用解耦PPO算法,有效分离生成策略和训练策略,使得AReaL-boba²在处理过时数据时,仍能够保持精度和稳定性。这一设计不仅提高了算法收敛的速度,也增强了系统的整体可扩展性。
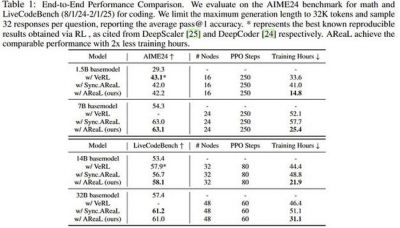
在实测过程中,AReaL-boba²表现出显著的训练速度优势。在使用128卡对1.5B参数规模的模型进行训练时,异步方法相比传统同步方法,平均每个训练步骤的耗时减少了52%。同时在多项编程领域的基准测试中,该系统同样展现了出色的性能,具体数据显示在某些任务上的吞吐量甚至提升了近2.77倍。
AReaL-boba²的可扩展性使其在处理大规模文生成任务时表现优异,通过异步生成机制有效提升整体效率。这使得该系统在承担多轮、长上下文、高复杂度智能决策任务时,能够提供更为稳定的训练支持。
对于开发者而言,AReaL-boba²不仅提供了丰富的开源代码、数据集和模型权重,还附带详细的教程和文档。这一完善的资源支持,旨在帮助开发者更快速、便捷地使用与定制其系统,使得更多的实际应用得以快速落地。同时,该团队始终坚持“全面开源、极速训练、深度可定制”的开发理念,使得AReaL-boba²不仅是一项科研成果,更成为了创新推动产业发展的强大引擎。
随着异步强化学习技术不断成熟,AReaL-boba²期待在更广泛的应用场景中展现其潜力,为未来智能体系统的优化提供更高效、更稳定的训练机制。各种复杂任务的解决方案将因此变得更加可行,而这一切的基础,正是清华大学与蚂蚁技术研究院的创新努力与坚持。
