OpenAI推出o3推理模型 实现图像与文本深度融合
时间:2025-06-07 07:30
小编:星品数码网
近日,OpenAI正式推出了其新一代o3推理模型,这一突破性技术使得多模态模型的推理方式焕然一新。o3不仅突破了传统的文本推理方法,首次将图像信息融入推理过程,实现了“以图思考”的全新模式。这一进展标志着视觉与文本推理的深度融合,为复杂问题的解决提供了全新的思路。
o3模型具备强大的视觉理解和推理能力,能够在具体应用中展现出惊人的表现。例如,当面对一张复杂的物理试卷时,o3能够自动定位公式区域,分析变量之间的关系,并结合已有知识推导出正确答案。在处理建筑设计图纸时,o3甚至可以实时调整图像的视角,判断结构的承重设计是否合理。这种精确且灵活的推理方式使得o3在视觉推理基准测试V Bench上实现了95.7%的高准确率,再次刷新了多模态模型的推理上限。
尽管o3的强大能力引人注目,但OpenAI并未详细披露其赋予o3如此能力的具体技术细节。根据一些专家分析,o3可能采用了端到端的强化学习方法,在不依赖监督微调(SFT)的情况下,激发了大模型“以图深思”的潜能。相关研究的论文和项目地址已在公开上发布,学术界和工业界均对这一模型的内在机制展开了热烈讨论。
在多模态模型方面,受R1的启发,近年来出现了不少以文本为核心的推理方式。这种的方法通常先观察图像,然后通过纯文本推理来解决复杂问题。这种方式也存在显著的缺陷,模型一旦进入推理阶段,就无法回头验证或补充细节信息,这常常会导致理解上的偏差或信息缺失。因此,更具前瞻性的思考方式应当是能够在推理过程中动态调用图像信息,实现视觉与语言之间的交互,从而大幅提升模型对细节的理解能力。
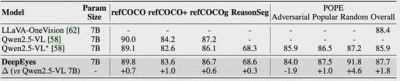
以DeepEyes为例,该模型通过“自驱动视觉聚焦”机制在推理流程中结合了图像分析能力。在解决问题时,DeepEyes建立初步的思维链。例如,在判断“手机与背包的位置关系”的问题时,模型会生成关于如何在图像中定位相关物体的内部推理逻辑。如果问题涉及小物体或模糊区域,DeepEyes会自主生成边界框,裁剪出可能包含关键信息的区域并聚焦分析。这一流程不仅提升了理解的准确性,也增强了模型的视觉上下文感知能力。
从生物进化的视角来看,DeepEyes的能力形成路径与传统的训练方式大相径庭。就像生活在约3.75亿年前的提塔利克鱼并非通过模仿其他生物而获得生存能力,而是在面临环境重大挑战时进化出了全新的适应机制。类似地,DeepEyes通过精心设计的数据集,以激励模型在训练过程中不断探索和学习,逐步形成复杂的图像推理能力。
在数据集的构建上,DeepEyes遵循三个原则:剔除过于简单或复杂的问题;优先选择能够通过图像分析工具提高信息增益的样本;,补充传统的推理数据以维持模型的综合能力。在这样的背景下,学习过程呈现出三个阶段的发展:初期像新手一样胡乱选择区域,接着在不断尝试中逐渐提高准确率,最终实现精准的区域判断和高效的推理。
深度学习的发展推动了视觉推理的革命,DeepEyes展示了多模态推理模型的新范式。与传统的基于工作流或监督学习的数据模型相比,DeepEyes具有相较低的数据获取门槛,且其端到端的学习策略显著提升了跨任务泛化能力和整体性能。DeepEyes在视觉理解能力及数理推理能力方面的显著提升,预示着多模态模型的进一步发展潜力。
通过原生的视觉定位能力,DeepEyes可以在不依赖外部工具的情况下,自动执行“图像思考”流程。对于需要更高精准度的任务,它同样能够调用辅助工具,确保在推理时减少信息的缺失和偏差。整体来看,DeepEyes在多个视觉推理任务中已展现出与o3相媲美的能力,帮助推动开放世界多模态智能应用的探索。
总体而言,OpenAI的o3推理模型不仅娓娓道出了图像与文本之间深度融合的可能性,还为我们的生活和工作打开了新的思维方式。随着多模态模型的不断演进,未来我们将迎来更加智能和高效的机器学习应用。
