中国DeepSeek模型展现算力与成本优势,助力AI产业发展
时间:2025-03-01 14:00
小编:星品数码网
近日,由浙江大学王则可教授撰写的一份报告引起了广泛关注,报告深入探讨了DeepSeek模型在算力和成本方面的显著优势,以及其在人工智能领域的重要意义和未来发展潜力。这一研究为理解中国大模型的发展提供了宝贵的视角,同时也为国内人工智能产业的未来发展指明了方向。
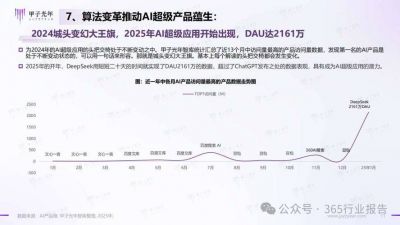
DeepSeek模型的优势在最新版本DeepSeek V3中得到了充分体现。在训练成本方面,DeepSeek V3的表现可以用“出色”来形容,与商业界广泛关注的Llama 3.1相比,DeepSeek V3的训练成本显著降低,仅达560万美元,GPU所需时间为280万小时,而Llama 3.1的训练成本则高达6200万美元,GPU时间为3100万小时。这一差距不仅表明了DeepSeek在经济性上的优势,也说明了其在算力利用上的高效性。
在技术创新层面,DeepSeek采用了MoE(Mixture of Experts)和MLA(Memory Layer Architecture)等前沿技术。通过MoE策略,DeepSeek能够利用一个共享专家来捕获通用知识,256个路由专家进行灵活表达,从而将每个Token的处理需求控制在360亿参数以内,这一数量远低于Llama 3.1的4050亿参数。这种显著的参数减少,使得DeepSeek在计算量上大幅降低,为提高模型的训练和推理效率提供了保障。DeepSeek的MLA技术通过对KV Cache的低秩压缩,成功降低了93.3%的空间占用,这不仅提升了推理性能,还有效降低了成本,展现了其在硬件限制情况下的技术优势。
在系统优化方面,DeepSeek自研了一套轻量级框架,采用FP8训练来提升算力密度,并通过DualPipe技术使得通信和计算高度重叠。DeepSeek还通过PTX优化技术部分绕开了CUDA的限制,尽管没有完全解决,但为国产硬件设计提供了新的思路。这一系列技术创新不仅增强了模型的实用性,也为国内大模型的发展提供了切实可行的路径。
值得关注的是,DeepSeek的快速发展也蕴含着其未来的无限可能。从整个发展历程来看,DeepSeek模型持续演进,模型规模和训练Token数量持续增加,技术水平不断提升。虽然未来在模型性能上可能会面临一些挑战,但在成本控制方面,其优势依旧明显。随着中芯国际等企业在工艺技术上的突破,以及华为对算力支持的不断提升,中国的大模型有望在全球AI竞赛中逐渐取得良好成绩,实现技术突破和商业盈利的双重目标。
DeepSeek在算力受限的现实挑战中,通过算法与系统的协同优化,成功实现了成本控制与性能提升的有机结合。这一成就不仅为配置有限的计算资源的企业提供了可行路径,还有望为打破国外技术垄断,推动中国的人工智能产业发展提供强有力的支撑。随着国内技术的不断进步,以DeepSeek为代表的国产大模型有望在全球AI领域占据更加重要的地位,为中国在国际竞争中赢得一席之地。
DeepSeek模型的成功,不仅仅体现在科技水平的提升,更在于其在算力与成本层面展现出的巨大潜力。这一成果为国内的人工智能产业带来了新的动力和希望,同时也为全球人工智能的未来发展指明了方向。随着技术的不断进步,DeepSeek及其背后的中国AI生态系统,必将在全球科技竞争中展现出更为耀眼的光芒,推动整个行业继续前行。
