中国开源大模型DeepSeek-V3引发全球关注,低成本训练成效显著
时间:2025-01-01 22:10
小编:星品数码网
在人工智能领域,来自中国的一款新兴开源大模型DeepSeek-V3近期引发了国内外的广泛关注。这款模型由新兴AI公司DeepSeek研发,凭借其卓越的性能和显著低廉的训练成本,迅速在业界引发了一轮热议。
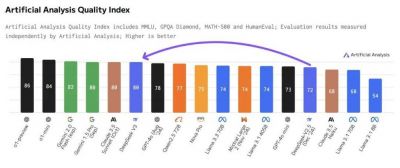
据DeepSeek发布的技术论文显示,DeepSeek-V3的参数规模从其前代模型的2360亿提升至6710亿,预训练时使用了14.8T tokens的数据集,而其上下文长度更是达到了128K。这些技术规格让DeepSeek-V3成为目前开源模型中的佼佼者。在多个主流评测基准上,该模型的表现与OpenAI的GPT-4o和Claude-3.5-Sonnet等知名闭源模型不相上下,为其赢得了“全球最佳开源大模型”的美誉。
DeepSeek-V3不仅在技术指标上表现出色,其开发过程中的成本控制同样引人注目。根据业内人士透露,该模型在训练过程中仅使用了2000多张GPU,训练总成本不到600万美元。这一成本远低于OpenAI和Meta等大型科技公司在数万个GPU上进行模型训练时所需的巨额投入,这一明显的成本优势为DeepSeek-V3的推广奠定了基础。
多位AI领域的专家和学者对DeepSeek-V3表示高度认可,阿里前副总裁贾扬清、Meta AI科学家田渊栋、英伟达高级研究科学家Jim Fan等业界大咖纷纷给予好评。部分网友更乐观地预测,该模型的问世将极大地推动通用人工智能(AGI)的实现进程,可能以更快的速度和更低的成本超越预期。
在具体的知识能力方面,DeepSeek-V3同样展现了其卓越性能。在MMLU-Pro和GPQA-Diamond等基准测试中,该模型的表现超越了阿里、Meta等所有开源模型,并在某些测试中领先于GPT-4o。不过,DeepSeek-V3在某些方面尚有待提高,特别是在英语理解能力上,依然落后于GPT-4o和Claude-3.5-Sonnet。
值得一提的是,DeepSeek-V3在数学、代码和推理能力方面的优异表现更是瞩目。在MATH500、AIME2024和Codeforces等多个主流基准测试中,DeepSeek-V3的结果不仅碾压了阿里和Meta的最新开源模型,还超越了GPT-4o和Claude-3.5-Sonnet,力证了其技术实力和应用潜力。
DeepSeek-V3也面临着不小的挑战。例如,其在部署方面的要求较高,对技术条件有限的小型团队或初创企业可能并不友好。该模型在生成速度方面仍有提升空间,可能影响其在实际应用中的效率。DeepSeek公司在论文中表示,随着更先进计算硬件的开发,这些局限性有望得到逐步解决。
在未来的发展方向上,DeepSeek及其团队正致力于进一步完善DeepSeek-V3,提高其在多种语言下的表现,使其更加适应全球市场的需求。同时,他们也计划持续优化模型的训练架构,以进一步降低成本并提升训练效率。
对于今后的研究与开发,DeepSeek团队表示,将致力于构建更多开源的AI工具,以推动整个生态系统的发展。他们相信,开源模型不仅能激发技术创新,还能帮助更多的开发者和研究团队获取最前沿的技术,进而加速人工智能技术的广泛应用和深化发展。
DeepSeek-V3的推出标志着中国在开源大模型领域的重要突破,而其在性能和成本双重优势下的成功,或将推动全球人工智能行业的全新变革。随着更多开发者和科研人员的参与,该模型有望在未来的人工智能研究中发挥更加重要的作用。
