上海AI实验室与高校联合研发新技术解决强化学习策略熵崩溃问题
时间:2025-07-13 16:30
小编:星品数码网
上海人工智能实验室近期与清华大学、伊利诺伊大学香槟分校等高等学府组成了一个国际研究团队,旨在突破强化学习领域中的一个重要难题——策略熵崩溃。借助Clip-Cov和KL-Cov两项新技术,该团队成功开发出有效的解决方案,标志着强化学习在应用潜力和理论深度上的进一步提升。
近年来,大型语言模型(LLMs)在推理能力上的表现愈加卓越,使得强化学习的应用场景不断扩展,从单一任务逐步向更为复杂的多任务环境发展。这一进展不仅提升了模型的泛化能力,还增强了其逻辑推理的能力。与传统模仿学习相比,强化学习对计算资源的需求更为严苛,主要体现在其对经验学习的依赖程度上。
强化学习的核心在于策略熵,这一指标能够反映出模型在利用已有策略与探索新策略之间的平衡。在训练过程中,策略熵的下降常常会导致模型对现有策略产生过度依赖,进而损失探索的能力。一旦熵值过低,模型表现出趋于“固执”的现象,无法适应新环境和新挑战。这种探索和利用的权衡(exploitation-exploration trade-off)正是强化学习的基本原则,因此控制策略熵的动态变化成为了训练过程中的一个重要挑战。
为了解决这一难题,上海人工智能实验室的研究团队提出了一个创新的经验公式R = −a exp H + b,其中H表示策略熵,R则代表下游任务的表现,a和b为拟合系数。这一公式揭示了策略性能与熵值之间的微妙权衡,明确了熵的耗尽是性能提升的瓶颈所在。
进一步的研究中,团队分析了熵的动态变化,发现其变化受到动作概率与logits(神经网络输出的未归一化值)之间协方差的驱动。为了维持熵水平,团队创新性地推出了Clip-Cov与KL-Cov技术。Clip-Cov技术主要通过裁剪高协方差的token来抑制策略熵的过度下降;而KL-Cov则是施加Kullback-Leibler(KL)惩罚,以此保持熵值在较高水平。
在这些新技术的支持下,研究团队采用了Qwen2.5模型和DAPOMATH数据集进行实验,涵盖了多个数学任务。实验结果喜人:在7B和32B两个模型上,性能分别提升了2.0%和6.4%。尤为值得注意的是,对于AIME24和AIME25这两个高难度基准测试,32B模型的性能提升甚至高达15.0%。这些成果不仅证明了Clip-Cov和KL-Cov技术的有效性,同时也为未来强化学习在语言模型中的更广泛应用奠定了理论基础。
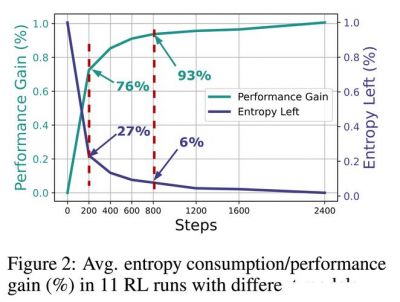
研究团队还对包括Qwen2.5、Mistral、LLaMA、DeepSeek等11个开源模型进行了广泛的测试,这些模型的参数规模从0.5B到32B不等,覆盖了数学和编程任务的8个公开基准测试。实验采用veRL框架和零样本设置,与GRPO、REINFORCE++等算法结合优化策略性能,验证了新技术的效果。结果表明,Clip-Cov和KL-Cov技术能够有效维持更高的熵水平,例如,KL-Cov方法在基线熵值趋于平稳时仍能保持10倍以上的熵值,这一发现对未来强化学习的发展具有重要意义。
研究团队不仅成功解决了策略熵崩溃问题,还为强化学习在大型语言模型中的扩展提供了理论支持。这项研究强调了熵动态在性能提升过程中的重要性,未来的工作将继续聚焦于熵管理策略的探索,以推动更智能的语言模型发展。随着技术的不断进步,强化学习在不同行业和领域的应用前景将更加广阔,为人类的智能决策与自动化提供支持。
此项研究的成果将为强化学习领域带来新的转机,同时也为相关学术研究和应用开发提供了丰富的思路和路径。期待未来看到更多创新技术的突破以及其在更广泛场景下的应用。
