华为DeepSeek V3推理性能突破,技术报告重磅发布
时间:2025-07-01 05:05
小编:星品数码网
在人工智能领域的迅速发展中,华为凭借其最新的DeepSeek V3模型,推理性能实现了新的突破,尤其是在超大规模MoE(Mixture of Experts)模型的部署中,展现出了令人瞩目的能力。根据新发布的技术报告,DeepSeek V3不仅在推理性能上实现了飞越,甚至达到了与英伟达Hopper架构相媲美的表现,标志着行业的一次重大进步。
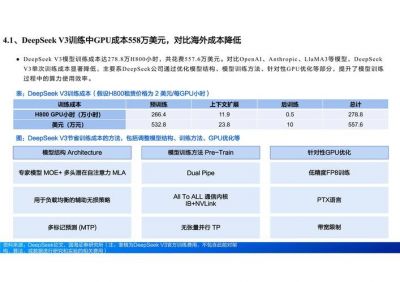
深入分析DeepSeek V3的技术实力
要了解DeepSeek V3实现如此强大推理性能的原因,必须明白当前大语言模型(LLM)推理能力在行业中的地位。自2017年Google提出Transformer架构以来,普遍关注的焦点已逐渐转向大模型在实际应用中的推理效果和效率。各大企业纷纷参与到这一竞争中,谁能在大模型的推理速度、稳定性和资源消耗上取得优势,谁就能在商业化浪潮中占据主动。
例如,DeepSeek V3模型拥有6710亿个参数,其复杂性给硬件部署带来了三大主要挑战:
1. 超大规模模型中的专家数量多,每个专家占用2.5G内存,这对普通的64GB内存AI硬件而言,是巨大的压力。
2. 专家分布在不同芯片上,数据传输的延迟往往超过计算的时间,导致整体效率降低。
3. 使用多头隐式注意力机制(Multi-Head Implicit Attention, MLA)时,虽然压缩了数据空间,但也增加了中间变量,给芯片的计算能力带来了更高的要求。
应对挑战的解决方案
为了解决这些挑战,华为团队从多个层面进行了深入研究与开发,制定了统筹规划的方案。其解决方案主要包括以下几个方面:
1. 硬件部署优化:华为根据不同硬件配置(如Atlas 800I A2和其他设备)采取了个性化的部署策略,以应对不同的时延约束条件。
2. 框架控制:在框架层面,华为采用了vLLM框架,通过调整 Prefill 调度与分层传输等技术来优化调度开销,提高系统性能。
3. 模型量化:通过A8W8C16量化策略,华为进一步降低了内存需求,提高了模型的运行效率,这对于处理多分布式任务至关重要。
华为的团队采用了大规模专家并行的方式,以16张卡进行Prefill和144张卡进行Decode,依托于128卡路由专家和16卡共享专家,最终在50ms的时延条件下,实现了单卡Decode吞吐率高达1920 Tokens/s的目标。
更广泛的优化策略
除了上述基本方案外,华为还提出了许多高级优化技术,成功应对了高并发场景下的挑战。例如,针对API Server的性能瓶颈,设计了横向扩展方案,显著降低了用户请求的延迟。针对MoE模型中负载不均的问题,华为实现了动态专家部署与实时监控机制,以此来实现负载的均衡分配。
在推理过程中,华为还提出了FusionSpec投机推理引擎,优化了多Token预测(MTP)场景下的推理性能,并通过针对性调整推进、低时延高效通讯等技术手段,进一步提升了通信的效率。这些项目旨在降低整体数据传输的频次和带宽占用,减少计算和通信过程中的冗余,使得描述复杂问题的任务变得更加高效。
与未来展望
随着技术报告的发布,华为在超大规模MoE模型推理性能上的提升,不仅彰显了其在AI领域的技术领导地位,也为未来更广泛的应用提供了实践基础。可以预计,随着更多核心技术的开源与共享,华为将继续在人工智能特别是大模型领域引领潮流。
这份重磅发布的技术报告,让我们看到了华为在技术创新方面不懈努力的成果,也为行业内其他企业树立了标杆。无论是理论框架的设计,还是实际操作的应用,华为都展示出了极大的前瞻性与创造力。的日子,随着更多技术的逐步公开,期待华为在推动AI技术不断进步的道路上继续奋勇向前,引领行业新方向!
