“排行榜幻觉”论文揭露大模型竞技场可信度危机
时间:2025-06-30 02:30
小编:星品数码网
在当今快速发展的人工智能领域,“大模型竞技场”作为评估和比较语言模型(LLM)表现的重要,长久以来受到科研界和产业界的广泛关注。最近一篇题为《排行榜幻觉》(The Leaderboard Illusion)的论文引发的争议,对这一的可信度提出了严峻质疑。
这篇论文指出,现阶段被视为权威排行榜的Chatbot Arena实际上存在诸多系统性问题,这些问题背后透露出大模型厂商在竞争中可能采取的不透明行为。这引发了业内对公平性和数据公正性的深刻思考。
研究发现,某些大型科技公司(如Meta、Google和Amazon)能够在私下测试多个模型版本,并只公布表现最佳的结果。这种“最佳模型选择”策略往往会导致排行榜的分数膨胀,使得最终榜单的真实性受到怀疑。例如,Meta在推出Llama 4之前私下测试了多达27个变体,而如果不限制这种测试变体的数量,模型评分将大幅提升,给排行榜带来了不小的偏差。
另一项令人关注的发现是,数据访问的不平等,让一些专有模型获取用户反馈的能力显著强于开源模型。在这场竞争中,Google和OpenAI获得的数据量分别高达19.2%和20.4%,而83个开放权重的模型仅占29.7%。这使得以公开模型为背景的排行榜更加难以反映真实的用户偏好。
论文还指出,依赖于竞技场数据训练的模型,其性能普遍更佳。这意味着,部分大厂通过“数据优势”来提升排名,让整个竞技场的公平性进一步受到挑战。例如,有数据显示,将训练数据比例提高至70%后,某个模型在特定任务上的胜率从23.5%提升至49.9%,这表明排名的提升并不完全源于模型本身的进步。
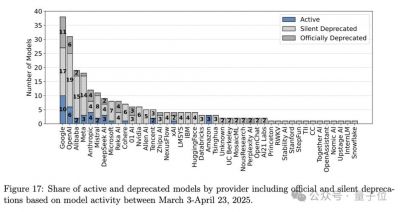
更让人震惊的是,在243个公开模型中,有205个被静默弃用,这个比例远高于官方透露的47个。这种贬值处理特别影响了开源和开放权重的模型,使榜单排名的准确性受到严重干扰。
针对研究中的质疑,大模型竞技场的官方LMArena.ai回应称,确实存在为厂商提供测试支持的情况,但这并不意味着竞技场本身有偏见。官方认为排行榜反映了数百万人类用户的真实偏好,并且坚称其政策是公开透明的。
尽管如此,论文提出的研究产生了广泛的关注,业内专家和学者纷纷表示,不能仅依赖单一的评估标准。在此背景下,知名AI专家卡帕西也表达了他的看法,他指出:“竞技场不应该是唯一的基准参考。”他提出一个替代方案OpenRouter,可以统一访问不同模型,并更加关注实际应用效果。
在这场关于信任和透明度的讨论中,如何改进大模型竞技场、提升其准确性和可信度成为了亟待解决的问题。研究团队也针对现存问题提出了5点改进建议,包括禁止伪造撤回分数、限制厂商非正式模型数量、实现公平的模型弃用政策等。这些建议引发了对未来模型评估体系的思考,也为AI社区带来了启示。
尽管大模型竞技场在提升用户体验及比较不同模型方面具有一定优势,但其使用过程中所暴露出的各种问题不容忽视。AI行业的持续健康发展,在一定程度上依赖于对评估方法的严格审视与改进。我们可能需要更为多样化且透明的模型评估机制,以便更好地反映出不同模型的真正实力和用户需求。在这一过程中,科研与实践的发展也必须保持步伐一致,才能稳步推进人工智能技术的进步与应用。
随之而来的,将是一个多元化的模型评估 universe,其中不仅包括大模型竞技场,还有其他新兴的衡量,只有这样,才能为用户提供更加真实、准确的模型能力评估。
在此背景下,我们要感谢《排行榜幻觉》这篇论文,它不仅揭示了大模型竞技场可能存在的诸多问题,更提醒了我们在关注AI技术进步的同时,也不能忽视实用性和透明度的提升。这是一个值得整个AI社区深思的时代,未来的道路更需要共同的努力与探索。
