阿里实验室推出开源强化学习框架 提升大模型检索能力
时间:2025-06-14 23:30
小编:星品数码网
在当前人工智能的迅速发展中,强化学习(Reinforcement Learning, RL)被广泛应用于各个领域,尤其是在自然语言处理和大规模模型的检索能力提升方面。最近,阿里通义实验室推出了一种开源强化学习框架,旨在利用 RL 技术持续提升大型模型在检索和推理任务中的表现,标志着这个领域的新进展。
强化学习与真实搜索引擎的挑战
虽然强化学习在多个应用场景中显示出极大的潜力,但是在与真实搜索引擎结合时却面临诸多挑战。真实搜索引擎所返回的文档质量往往不稳定,带来了训练过程中难以控制的噪音和不确定性。这就使得强化学习模型在训练时无形之中产生了更多复杂性,可能导致模型的推理能力下降。强化学习的训练通常需要频繁调用外部搜索引擎 API,这不仅增加了成本,还对模型的可扩展性造成了限制。
阿里实验室的创新解决方案
为了解决上述问题,阿里通义实验室的研究团队提出了一种创新的强化学习框架,采取开放源代码的方式进行发布。实验证明,仅需使用 3B 参数的 LLM(大语言模型)作为检索模块,便能够有效提升搜索能力,且显著降低了对昂贵 API 调用的依赖。
1. LLM自我演进
该框架的设计理念是让大型语言模型在特定的训练流程下,能够逐渐适应并提升自身的检索能力,从而形成一个“自给自足”的搜索生态系统。研究团队采用了轻量微调的方法,只需少量标注数据便可将 LLM 训练为“搜索引擎模拟器”。模型通过与真实搜索引擎的交互,逐步学习到如何生成与真实搜索引擎风格相似的文档,并能够根据提示生成相关或噪声文档。
2. 课程化抗噪训练
该框架还引入了课程化抗噪训练策略,使得模型在训练过程中能够以“打游戏升级”的方式逐步适应更复杂的任务。在训练的初期,模型返回高质量文档,而在后期则逐渐混入噪声数据,噪声比例以指数曲线方式逐渐上升。这样的设置不仅提升了模型的推理能力,还显著提升了训练的稳定性。通过不断调整训练难度,模型最终能够在高质量和低质量文档之间找到一个合适的平衡点,从而提高检索效果。
3. 完善的强化学习闭环
通过构建完整的强化学习闭环,阿里实验室的框架消除了与真实搜索引擎交互的 API 费用,使得大规模强化学习训练具有更加经济性和可行性。该框架支持多种强化学习算法,包括 PPO(Proximal Policy Optimization)和 GRPO(Group Relative Policy Optimization),这些算法为模型提供了不同的优化策略,可以在多种模型和任务中展现出卓越的表现。研究显示,GRPO 在训练的稳定性方面表现更优越,而 PPO 则在灵活性较高的任务中有更好的效果。
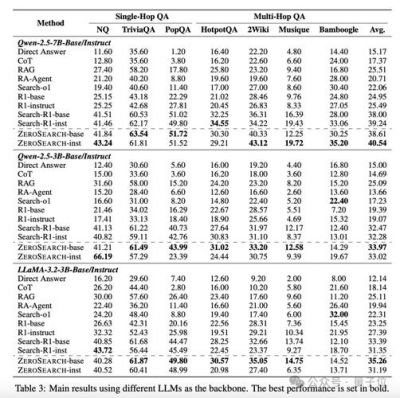
优越的实验结果
阿里通义实验室的研究结果显示,该框架在多项问答数据集上显著优于现有的方法,包括直接提示、RAG 和 Search-R1 等。无论是面对单跳(Single-Hop)还是多跳(Multi-Hop)问答任务,模型的表现都展示了强大的检索能力。这反映出该方法不仅可应用于简单的任务场景,更能在复杂的检索场景中展现强大的优势例。在对比学习曲线中,使用该框架的模型在稳定性和性能上均优于使用真实搜索引擎的模型,显示出更高的训练有效性。
和未来展望
通过全面消除 API 成本,同时通过课程式学习策略提高模型的推理能力,阿里通义实验室的强化学习框架为提升大模型检索能力提供了新的思路和实践。随着技术的不断进步,该框架将能够适应更复杂的任务,为行业内的研究人员和开发者提供更丰富的选择。
可以预见,随着这一开源框架的推广应用,将有助于推动智能检索技术的不断演进,并为未来智能应用的开发奠定扎实的基础。研究团队的努力以及开放性思维值得业界的广泛关注与合作。
论文的第一作者孙浩目前是北京大学智能学院的博士研究生,专注于检索增强的大语言模型及智能体研究,师从著名教授张岩。有关该项目的更多信息,可以通过以下链接获取:
论文链接:[https://arxiv.org/abs/2505.04588](https://arxiv.org/abs/2505.04588)
项目主页:[https://alibaba-nlp.github.io/](https://alibaba-nlp.github.io/)
通过继续探索强化学习与大模型检索相结合的潜力,人工智能领域将迎来更加辉煌的未来。
